Como conversar con tus propios datos

Con el desarrollo de la reciente Inteligencia Artificial Generativa (genAI) los grandes modelos de lenguaje (LLMs) como el conocido ChatGPT, son capaces de responder preguntas sobre diversos temas. Para lograr esta funcionalidad estos modelos son entrenados con millones de datos de diversas fuentes. A pesar de ello, los LLMs una vez entrenados no son capaces de responder a preguntas específicas sobre datos personal, documentos o información más específica de propiedad empresarial o intelectual.
¡Imaginemos si pudiéramos tener conversaciones con nuestros propios datos o fuentes de información!
A través de una técnica de recuperación y generación de información (conocida como RAG por sus siglas en inglés) podemos usar los LLMs para tener conversaciones con nuestras fuentes de datos.
En el presente artículo vamos a explicar qué son los RAG y como son realmente útiles para lograr productividad en el sector empresarial.
RAG
Como sus siglas en inglés lo indican un RAG es un sistema que se compone de dos funcionalidades principales: recuperación de la información y generación aumentada de una respuesta. La recuperación de información es una rama de los sistemas de información donde a partir de una fuente de datos y una consulta se logra obtener aquella información que es más relevante respecto a la consulta establecida. Por otro lado, generación aumentada se refiere a un enfoque en el cual el proceso de generación de texto o respuestas se mejora mediante la incorporación de información adicional recuperada de diversas fuentes de datos.
En la actualidad los RAGs representan un enfoque novedoso en el campo de la inteligencia artificial ya que combinan la recuperación de información de grandes volumenes de datos y generación de texto. A diferencia de los modelos de generación de texto tradicionales que dependen únicamente de los datos con los que fueron entrenados, los RAGs integran mecanismos de recuperación de información que les permiten acceder y utilizar datos actualizados y específicos de diversas fuentes durante el proceso de generación de respuestas. Un modelo de recuperación busca y extrae información relevante de bases de datos o documentos, y un modelo de generación utiliza esta información para producir respuestas coherentes y contextualmente precisas. La combinación de ambas técnicas permiten crear respuestas más precisas, contextualizadas y útiles, ya que el modelo puede acceder a datos específicos y actualizados en tiempo real.
Los RAG son especialmente útiles dentro del sector empresarial ya que generan interacciones conversacionales con múltiples fuentes de datos. Al integrar capacidades de búsqueda avanzada, estos sistemas pueden proporcionar respuestas más informadas y precisas al acceder directamente a datos relevantes en tiempo real, lo que es crucial para entornos de trabajos dinámicos y basados en datos. Por ejemplo, en el servicio al cliente, un sistema basado en RAG podría consultar bases de conocimiento, manuales de productos y registros de soporte para ofrecer respuestas detalladas y precisas a las consultas de los clientes. Esto no solo mejora la eficiencia operativa, sino que también eleva la experiencia del usuario al proporcionar información exacta y actualizada en cada interacción.
A grandes rasgos la creación de un sistema RAG requiere los siguiente pasos:
- Carga de información
- División de la información
- Almacenamiento de la información
- Recuperación
- Respuesta a preguntas
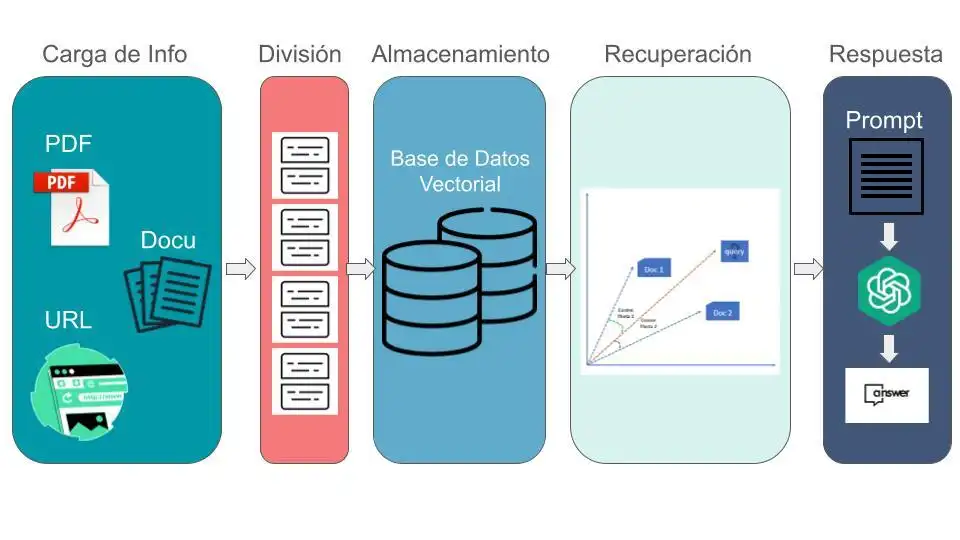
Cargando la información
Si queremos crear una aplicación para chatear con nuestros datos, primero debemos cargar nuestros datos en un formato con el que se pueda trabajar. Para ello Klari nos brinda una serie de funciones que permiten cargar información de diversas fuentes de datos. Los cargadores de documentos de Klari se ocupan de los aspectos específicos del acceso y la conversión de datos de una variedad de formatos y fuentes diferentes (pdf, html, docs, markdown….) a un formato estandarizado. Incluso sin importar si los datos se encuentran estructurados o no.
Dividiendo la información
Una vez cargado la información de la fuente de datos, es necesario dividirla en partes más pequeñas. Este proceso es fundamental ya que al utilizar los LLMs estos tienen una limitante en el número de información (tokens) que reciben como entrada. El proceso de división de información ocurre después de cargar los datos en un formato de documento estandarizado pero antes de que entren en la base de datos. Dividir documentos en partes más pequeñas es importante y complicado, ya que necesitamos mantener relaciones coherentes entre las partes. Por ejemplo, si una oración en un documento se divide en :
Parte 1: “La inteligencia artificial generativa surgió como una impactante novedad para el“
Parte 2: “mercado tecnológico y rápidamente se convirtió en una de las herramientas más adoptadas en todo el mundo”
En este caso, hicimos una división simple y terminamos con parte de la oración en un fragmento y la otra parte de la oración en otro fragmento. Por lo tanto, no podremos responder con precisión a una pregunta sobre el surgimiento de la “inteligencia artificial generativa” debido a la falta de información correcta en cualquiera de los dos fragmentos. Por eso es importante que dividamos la información en fragmentos semánticamente relevantes. El propósito de la división es tener texto con un contexto común que ayude a la recuperacón. Una división de texto a menudo usa oraciones u otros delimitadores para mantener unido el texto relacionado, pero muchos documentos (como Markdown) tienen una estructura (encabezados) que se pueden usar explícitamente en la división.
Almacenando la información
Una vez dividida la información en pequeños fragmentos, necesitamos colocar cada uno de estos en un índice para que podamos recuperarlos fácilmente cuando queramos responder preguntas sobre este documento. Con este propósito vamos a utilizar embeddings y Bases de Datos Vectoriales. Los embeddings y las bases de datos vectoriales vienen después de la división del texto, ya que necesitamos almacenar nuestros documentos en un formato de fácil acceso. Los embeddings son representaciones de vectores numéricos de un fragmento de texto dado. De esta manera, dos fragmentos de texto con contenido semánticamente similar tendrán una representación similar dentro del espacio vectorial. Esto facilita la tarea de comparar embeddings(vectores) y encontrar textos que sean similares.
Una vez obtenidos, cada uno de los vectores serán almacenados en una base de datos vectorial para facilitar el acceso. Esta característica de las bases de datos vectoriales resulta útil cuando intentamos encontrar documentos que sean relevantes para una pregunta. De esta manera, cuando queremos obtener una respuesta para una pregunta, creamos un embedding de la pregunta y luego lo comparamos con los embeddings almacenados en la base de datos vectorial para elegir los n más similares. Finalmente, tomamos los n fragmentos más similares y los pasamos junto con la pregunta a un LLM y obtenemos la respuesta.
Recuperación
La recuperación de información (Retrieval en inglés) es la pieza central de nuestro flujo de (RAG). La recuperación es uno de los mayores problemas que enfrentamos cuando intentamos responder preguntas sobre nuestros documentos. La mayoría de las veces, cuando falla la respuesta a nuestras preguntas, se debe a un error en la recuperación. La recuperación es importante en el momento de la consulta, cuando llega una consulta y queremos recuperar los textos más relevantes. Existen varios métodos de recuperación de información, entre los más utilizados encontramos:
- Acceder directamente a los datos de la base de datos vectorial: Como mencionamos anteriormente podemos consultar directamente a la base de datos vectorial y obtener los n documentos más similares. Sin embargo existen algunas mejoras a esta solución. Una de ellas es conocida como Relevancia Marginal Máxima (MMR por sus siglas en inglés). MMR es un método importante para imponer la diversidad en los resultados de búsqueda. En el caso de la búsqueda semántica, obtenemos documentos que son más similares a la consulta en el espacio de embedding, sin embargo podemos perdernos información diversa. La idea detrás de MMR es que primero consultamos el almacén de vectores y elegimos las respuestas “fetch_k” más similares. Ahora, trabajamos en este conjunto más pequeño de documentos “fetch_k” y lo optimizamos para lograr relevancia para la consulta y diversidad entre los resultados. Finalmente, elegimos la respuesta “k” más diversa dentro de estas respuestas “fetch_k”.
- SelfQuery: Es una herramienta importante cuando queremos inferir metadatos de la propia consulta. Podemos usar un LLM para extraer la cadena de consulta que se utilizará para la búsqueda de vectores y un filtro de metadatos para pasar también. De esta manera, se utiliza un LLM para filtrar resultados según metadatos. Este método se utiliza cuando tenemos una consulta no solo sobre el contenido que queremos buscar semánticamente sino que también incluye algunos metadatos a los que queremos aplicar un filtro.
- Compresión contextual: La compresión es otro método para mejorar la calidad de los documentos recuperados. Dado que pasar el documento completo a través de la aplicación puede generar llamadas de LLM más costosas y una peor respuesta, es útil extraer solo las partes más relevantes de las partes recuperadas. Con la compresión, ejecutamos todos nuestros documentos a través de un modelo de lenguaje y extraemos los segmentos más relevantes y luego pasamos solo los segmentos más relevantes a una llamada final al modelo de lenguaje. Esto tiene el costo de realizar más llamadas al modelo de lenguaje, pero también es bueno centrar la respuesta final solo en las cosas más importantes.
Respondiendo a preguntas del usuario
La fase final de un sistema RAG es la Respuesta a preguntas. En esta etapa, el objetivo es proporcionar respuestas precisas y contextualmente relevantes a las preguntas formuladas por los usuarios, utilizando tanto la información recuperada como las capacidades de generación de lenguaje de un modelo LLM (chatGPT por ejemplo). Expliquemos todo el proceso en estos 4 pasos.
- Integración de la información recuperada: Una vez que el sistema ha recuperado los fragmentos de información más relevantes de la base de datos, estos fragmentos se integran como contexto para el modelo LLM. Este paso es crucial porque permite que el modelo tenga acceso directo a la información específica necesaria para responder la pregunta del usuario.
- Generación de la respuesta: Con la información recuperada, el modelo LLM utiliza sus capacidades de procesamiento del lenguaje natural para generar una respuesta coherente y precisa. El modelo combina su conocimiento preexistente con los datos proporcionados, asegurando que la respuesta sea tanto informativa como específica al contexto de la pregunta.
- Verificación y ajuste: En algunos casos, puede ser necesario verificar la exactitud de la respuesta generada. Esto puede implicar un proceso de revisión adicional donde se comparan las respuestas generadas con la información recuperada para asegurar consistencia y precisión. En sistemas avanzados, este paso puede ser automatizado parcialmente, utilizando algoritmos que evalúan la coherencia y relevancia de las respuestas.
- Presentación de la respuesta: Finalmente, la respuesta generada por el modelo LLM es presentada al usuario. La presentación puede variar dependiendo del canal de comunicación utilizado (por ejemplo, texto en un chatbot, voz en un asistente virtual, etc.). Todo este proceso presenta una respuesta clara y fácil de entender para el usuario, proporcionando información útil y directa.
En conclusión, la implementación de sistemas RAG (Retrieval-Augmented Generation) representa un avance significativo en la capacidad de interactuar y conversar con datos propios. Como pudimos observar estas soluciones combinan de manera eficaz la recuperación de información específica y relevante con las capacidades generativas de modelos LLM, proporcionando respuestas precisas y contextualmente adecuadas. Para las empresas, esto se traduce en una herramienta poderosa que no solo mejora la eficiencia en la toma de decisiones, sino que también optimiza la experiencia del usuario al proporcionar información personalizada y relevante de manera rápida y fiable. La capacidad de conversar directamente con sus propios datos permite a las empresas aprovechar al máximo sus recursos informativos, facilitando la innovación y la competitividad en un entorno cada vez más orientado a los datos.


