Conversando con tus Datos: Potenciando la Interacción mediante Apache Airflow

En la era actual de la Inteligencia Artificial, la capacidad de poder interactuar conversacionalmente con nuestros propios datos, y poder preguntar sobre cualquier tema y obtener respuesta casi al instante se ha convertido en un objetivo clave.
Imaginemos poder buscar en un libro un párrafo específico que necesitamos en una biblioteca repleta en segundos. De ahí nace la capacidad de darle “Inteligencia” a Bots que puedan atender un teléfono casi con la misma información que puede tener un humano a su alcance. Como explicamos en nuestra nota anterior “Cómo conversar con tus propios datos”, queda claro que aún enfrentamos grandes desafíos cuando se trata de manejar datos específicos y personalizados.
En este contexto, la técnica de Recuperación y Generación Aumentada de Información (RAG) es fundamental. Nos permite encontrar de manera semántica el texto más relevante para enriquecer nuestras interacciones. Pero para que esta técnica funcione, necesitamos datos.
Uno de los principales retos es cómo cargar estos datos y obtener información útil de diversas fuentes (como PDF, Markdown, páginas web, etc.). En este artículo, exploraremos cómo Klari, a través de Apache Airflow, facilita esta integración. Analizaremos cómo esta plataforma ayuda a estructurar y almacenar información para luego recuperarla por medio de RAG.
¿Que es Apache Airflow?
Apache Airflow es una herramienta de código libre creada por Airbnb como solución para la gestión de flujos de trabajo dentro de la empresa. Al crear Airflow, Airbnb logró manejar más fácilmente sus flujos de trabajo y controlarlos gracias a su interfaz.
Airflow nos permite crear Grafos Acíclicos Dirigidos (DAGs), donde cada nodo del grafo es un script de python o bash que trabaja sobre un flujo de datos que va en una sola dirección.
Ejemplo de Aplicación
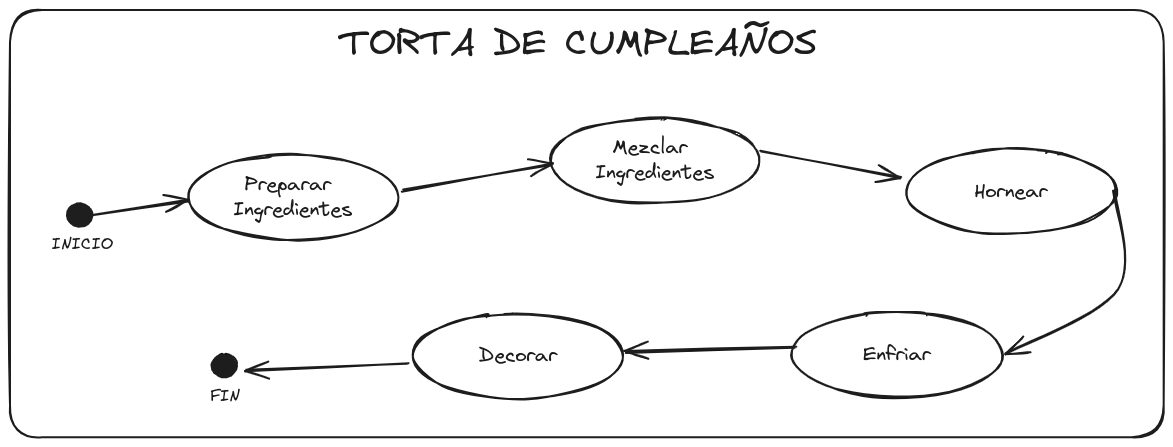
Imaginemos que queremos planificar la elaboración de una torta de cumpleaños como un DAG. Cada paso, desde preparar los ingredientes hasta decorar la torta, está diseñado secuencialmente. Por ejemplo, los ingredientes mezclados son los que se hornean, y así sucesivamente.
Ahora imaginemos que también queremos hacer pan. Obviamente incluirá pasos que debemos aprender, pero también hay pasos que ya sabemos hacer, como preparar ingredientes, mezclar ingredientes y hornear, por lo que solamente deberemos codificar el resto.
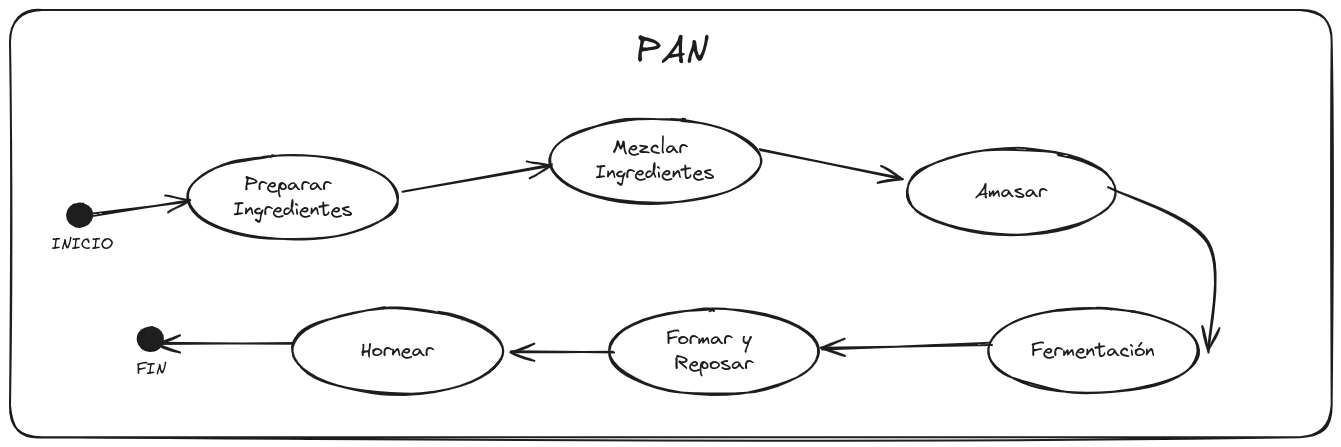
Esta es una de las grandes ventajas de este sistema: poder pensar cada paso como una unidad funcional que nos permita “conectar” y “desconectar” sus anteriores y posteriores pasos.
Klari con Apache Airflow
Klari permite incorporar documentos que serán la base de conocimiento para nuestros bots. Toda esa información se guarda de forma vectorial que luego Klari extrae a medida que las preguntas de los usuarios la van demandando.
Mientras más información esté cargada en nuestro bot, mejor será la calidad de las respuestas, ya que el bot tendrá contexto para poder armar sus respuestas basadas en esa información.
Es aquí donde entra la interacción con Apache Airflow. Klari tiene diseñado sus DAG’s que permiten extraer toda la información de los documentos y dejarla en un formato adecuado para que el bot pueda usarlo como conocimiento.
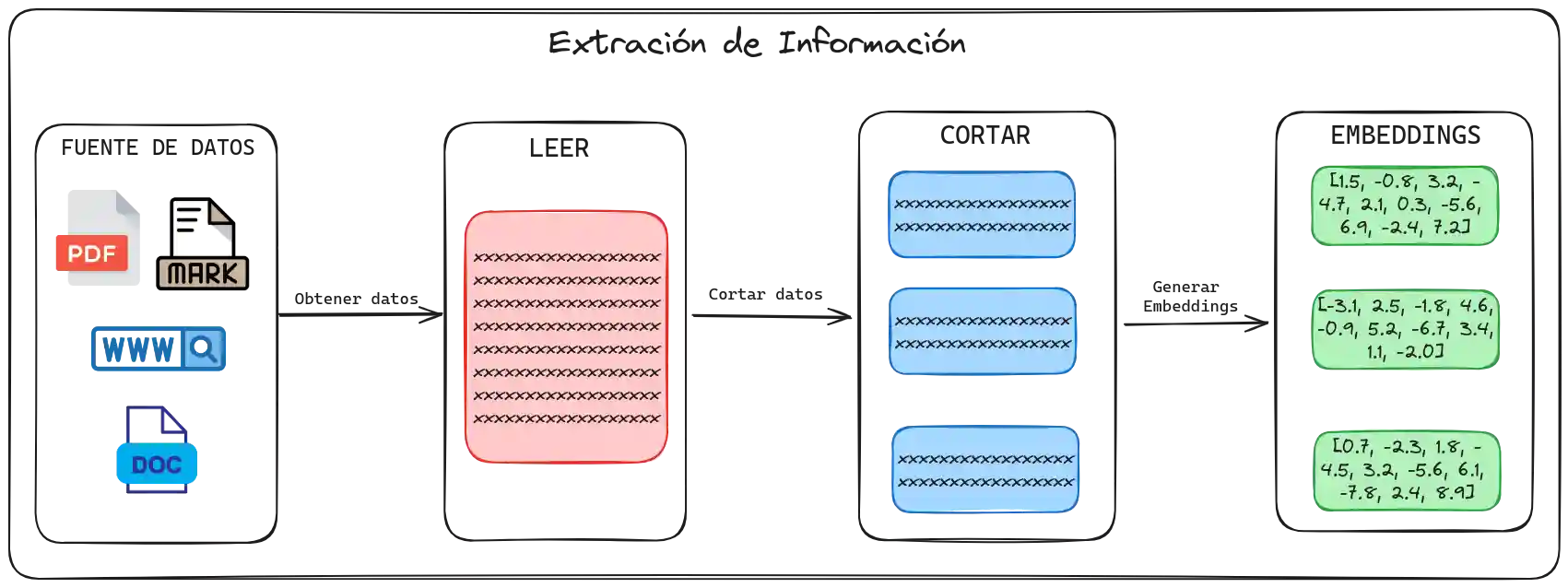
El proceso para conversar con tus datos puede dividirse en cuatro grandes pasos. Cada uno de estos pasos es un caso de estudio aparte, en cada uno de ellos nos encontraremos con muchas formas diferentes de hacerlo. En este blog, explicaré de manera general cada uno de esos pasos, pero pueden encontrar más detalles en la nota “Cómo conversar con tus propios datos”.
1. Carga de la fuente de datos
El primer paso del proceso consiste en cargar la fuente de datos. Esta fuente puede ser un archivo, como un documento de texto, pdf, excel, markdown, o una URL. En esta etapa, es importante asegurar que los datos están accesibles y en un formato que pueda procesarse posteriormente.
2. Extracción de información
El segundo paso es obtener información de la fuente que cargamos previamente. Esto implica procesar y extraer texto, imágenes, videos, o cualquier otro tipo de contenido que nuestra fuente nos ofrezca.
3. Cortar información
Una vez obtenida toda la información extraída, el siguiente paso es segmentar de manera adecuada para evitar inconsistencias o cortes inadecuados.
Por ejemplo, si estamos tratando con instrucciones de una receta, no podemos cortar un paso a la mitad. Existen varias estrategias para segmentar la información de forma efectiva, dependiendo del tipo de datos y el contexto.
Este paso es muy importante para asegurar que los datos estén en un formato utilizable y coherente para las siguientes etapas del proceso.
4. Generación de embeddings
El último paso es generar embeddings para cada uno de los segmentos. Los embeddings son representaciones vectoriales de los datos que permiten a los modelos de machine learning entender y procesar la información.
Con esto, Klari proporciona la capacidad de extraer información de los documentos y ponerla inmediatamente a disposición del bot. Esto transforma los datos en conocimiento accesible, permitiéndonos dar respuestas mucho más fundamentadas a las diversas inquietudes de los usuarios.


