Embeddings: El Corazón de la Conversación con los Datos

Embeddings: Si estás familiarizado con el mundo de la tecnología, probablemente hayas escuchado hablar de ellos. Para quienes no lo están, no se preocupen. Aunque suene complicado, mi objetivo es que al final de este artículo logren entender al menos los conceptos básicos de esta herramienta. Ahora si:
¿Qué son los embeddings?
En la era de los datos, la manera en que las máquinas entienden el lenguaje natural es vital para cualquier interacción entre humanos y sistemas. Aquí es donde los embeddings juegan un papel fundamental. Pero, ¿qué son exactamente?
Los embeddings son representaciones vectoriales densas de datos, como palabras, frases, párrafos o incluso documentos completos, en un espacio de dimensiones reducidas. Lo más interesante es que capturan las relaciones semánticas y sintácticas entre estos datos. Es decir, pueden “entender” cómo están conectadas las palabras o ideas entre sí.
Linda definición, ¿no? Ahora traduzcámosla:
Imagina que cada palabra tiene una “coordenada” en un mapa imaginario. Palabras con significados similares o relacionadas entre sí, como “rey” y “reina”, estarán cerca en este mapa. Por otro lado, palabras que no tienen mucha relación, como “rey” y “avión”, estarán más lejos.
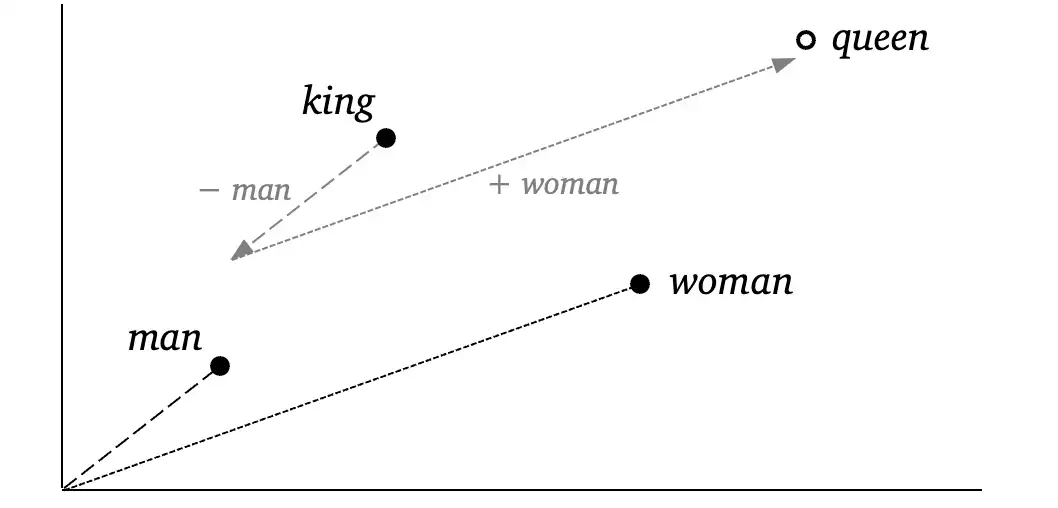
En esta representación sencilla en dos dimensiones, vemos varios puntos en el mapa. “Rey”, “Reina”, “Hombre” y “Mujer”. Estos puntos no fueron puestos al azar, si observamos detenidamente “Rey” está a la misma distancia vectorial de “Reina” que “Hombre” de “Mujer”. Esto se explica porque si al concepto de “Rey” le restamos el concepto de “Hombre” y le sumamos el concepto de “Mujer” nos da como resultado “Reina”. Esto que llamamos “conceptos” son vectores, en este caso de 2 dimensiones, que como todo vector nos permite hacer sus típicas operaciones.
¿Para qué sirven los embeddings?
Imaginemos que llega el fin de semana y no sabemos qué película ver, y como somos expertos en embeddings decidimos usarlo para elegir la película. Entonces decidimos clasificar todas las películas del mundo bajo 5 características principales.
- Acción
- Romántica
- Comedia
- Drama
- Ciencia Ficción
Elegimos representar cada característica en una escala del 0 al 1, donde 0 significa ausencia total de la característica y 1 significa presencia total.
Esto podemos llevarlo a un vector donde la dimensión 1 representará que tan de acción es la película, la dimensión 2 que tan romántica, y así sucesivamente.

Supongamos que tenemos tres películas:
-
Película A
- Acción: 0.7
- Romántica: 0.2
- Comedia: 0.1
- Drama: 0.4
- Ciencia Ficción: 0.8
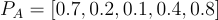
-
Película B
- Acción: 0.4
- Romántica: 0.6
- Comedia: 0.3
- Drama: 0.7
- Ciencia Ficción: 0.3
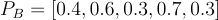
-
Película C
- Acción: 0.1
- Romántica: 0.8
- Comedia: 0.5
- Drama: 0.9
- Ciencia Ficción: 0.2
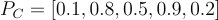
Supongamos que queremos ver una película que sea mayormente de acción, con un toque romántico y un poco de ciencia ficción. Podemos representar nuestras preferencias como un vector de embedding:
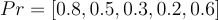
Una vez que hayamos generado los embeddings de todas las películas y definido el embedding con nuestras preferencias, este vector caerá en un punto específico dentro del espacio de embeddings. Las películas cuyos vectores estén más cerca de este punto serán las que mejor se ajusten a nuestras preferencias.
Aquí es donde entra en juego la similitud del coseno, una medida matemática que nos permite calcular la “distancia” entre dos vectores. Para los más técnicos, la fórmula de la similitud del coseno es la siguiente:
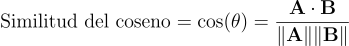
Donde:
- A⋅B es el producto punto de los vectores A y B,
- ∥A∥ y ∥B∥ son las normas de los vectores A y B.
Así, tendremos una lista de películas ordenadas de las más similares a nuestras preferencias a las menos similares. ¡Y listo! Ahora sabemos qué película ver.
Pero, ¿Cómo elegimos las características de los vectores?
El ejemplo que usamos anteriormente es una simplificación de cómo se utilizan los embeddings en la práctica. En el mundo real, la elección de las características para los vectores no se hace manualmente ni se limita a un conjunto predefinido como en nuestro ejemplo de las películas. En lugar de eso, se utilizan técnicas de machine learning para automatizar este proceso y capturar una gama mucho más amplia de relaciones semánticas y sintácticas.
En lugar de definir manualmente las características, se utilizan redes neuronales para aprender representaciones vectoriales. Estos modelos son entrenados con grandes volúmenes de texto, permitiéndoles aprender patrones y relaciones complejas entre palabras y frases a partir de los datos. A través del proceso de entrenamiento, el modelo ajusta los vectores de palabras de manera que reflejen sus significados y relaciones contextuales de forma más precisa.
Los embeddings generados por estos modelos no están limitados a características predefinidas. En su lugar, las características surgen de los datos durante el proceso de entrenamiento. Por ejemplo, un modelo puede aprender que la palabra “doctor” está relacionada con términos como “salud” y “hospital” a partir de su aparición en textos médicos, sin que estas relaciones sean especificadas explícitamente.
¿Cómo usamos esto en Klari?
En Klari, los embeddings juegan un papel muy importante en nuestra capacidad para ofrecer un servicio de atención al cliente ágil y efectivo. Utilizamos embeddings para mejorar la comprensión del lenguaje natural de nuestros agentes, lo que les permite interpretar y responder a las consultas de los clientes con una precisión sorprendente.
¿Qué beneficios trae esto?
Los embeddings permiten a nuestros agentes entender el contexto y el significado de las preguntas de los clientes, incluso cuando se formulan de manera inusual o con términos no tan comunes. Al buscar en el espacio de embeddings, nuestros agentes pueden encontrar respuestas que están semánticamente alineadas con la pregunta del cliente, lo que resulta en interacciones más satisfactorias y útiles.
Reflexión Final
Los embeddings son una herramienta poderosa que está transformando la forma en que interactuamos con los datos y el lenguaje. Desde recomendar películas basadas en nuestras preferencias hasta mejorar la precisión de los agentes de atención al cliente en Klari, los embeddings permiten una comprensión más profunda y precisa del lenguaje.
A medida que avanzamos en la era digital, la capacidad de las máquinas para “entender” y “responder” de manera más humana seguirá evolucionando. Los embeddings son solo una de las muchas innovaciones que están permitiendo que las tecnologías de inteligencia artificial se conviertan en asistentes más efectivos y comprensivos.


